CPU 缓存
CPU 缓存层级
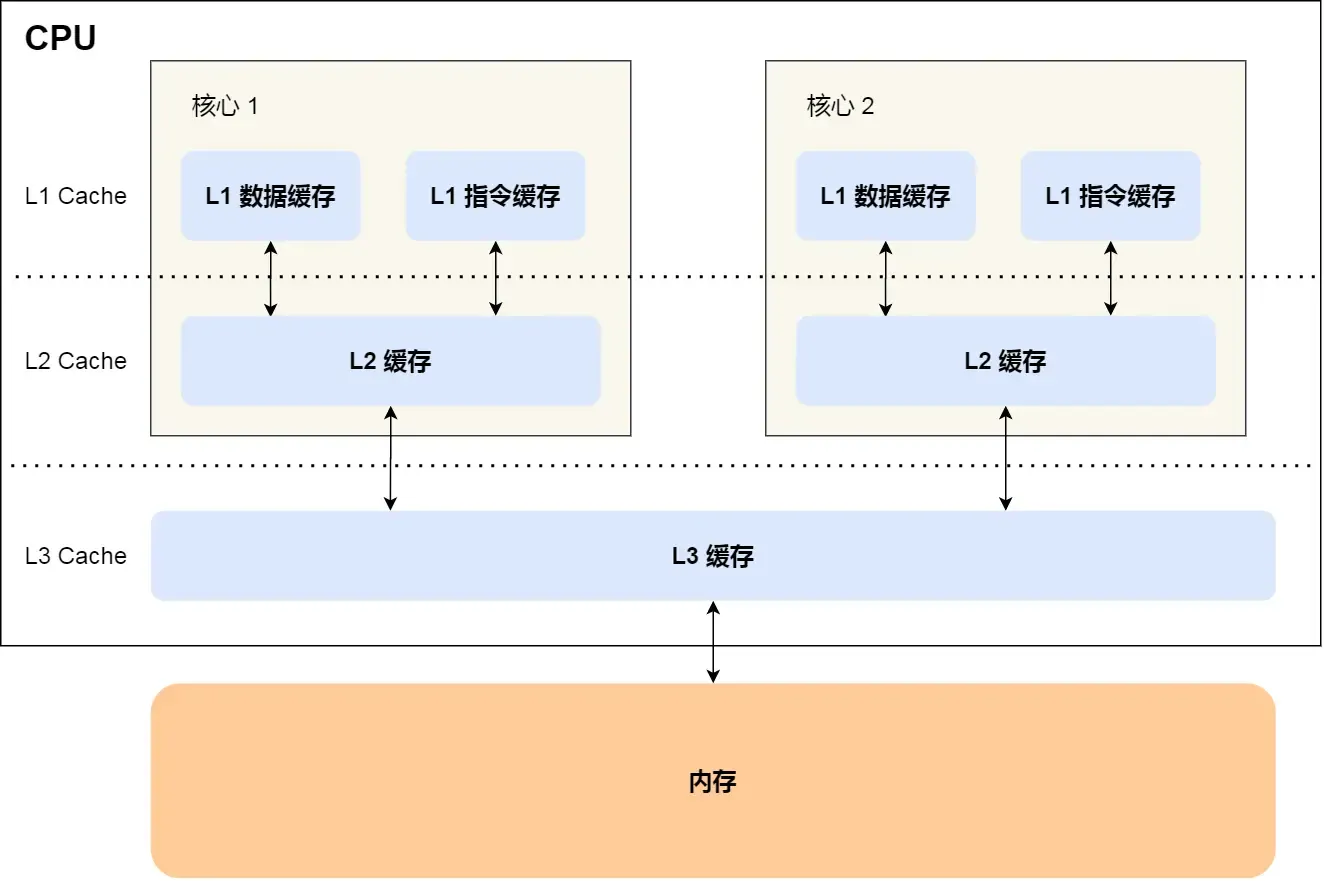
# index0 和 index1 是 L1 缓存,包含数据缓存和指令缓存
$ cat /sys/devices/system/cpu/cpu0/cache/index0/type
Data
$ cat /sys/devices/system/cpu/cpu0/cache/index1/type
Instruction
# L2 和 L3 是统一缓存,L1 和 L2 是核心独有的
$ cat /sys/devices/system/cpu/cpu0/cache/index2/type
Unified
# L3 缓存是多核心共享的
$ cat /sys/devices/system/cpu/cpu0/cache/index3/type
UnifiedCPU Cache 的数据结构和读取过程
Cache Line 是 CPU 从缓存读取数据的最小单位
# 这说明 Cache Line 大小是 64 字节
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
64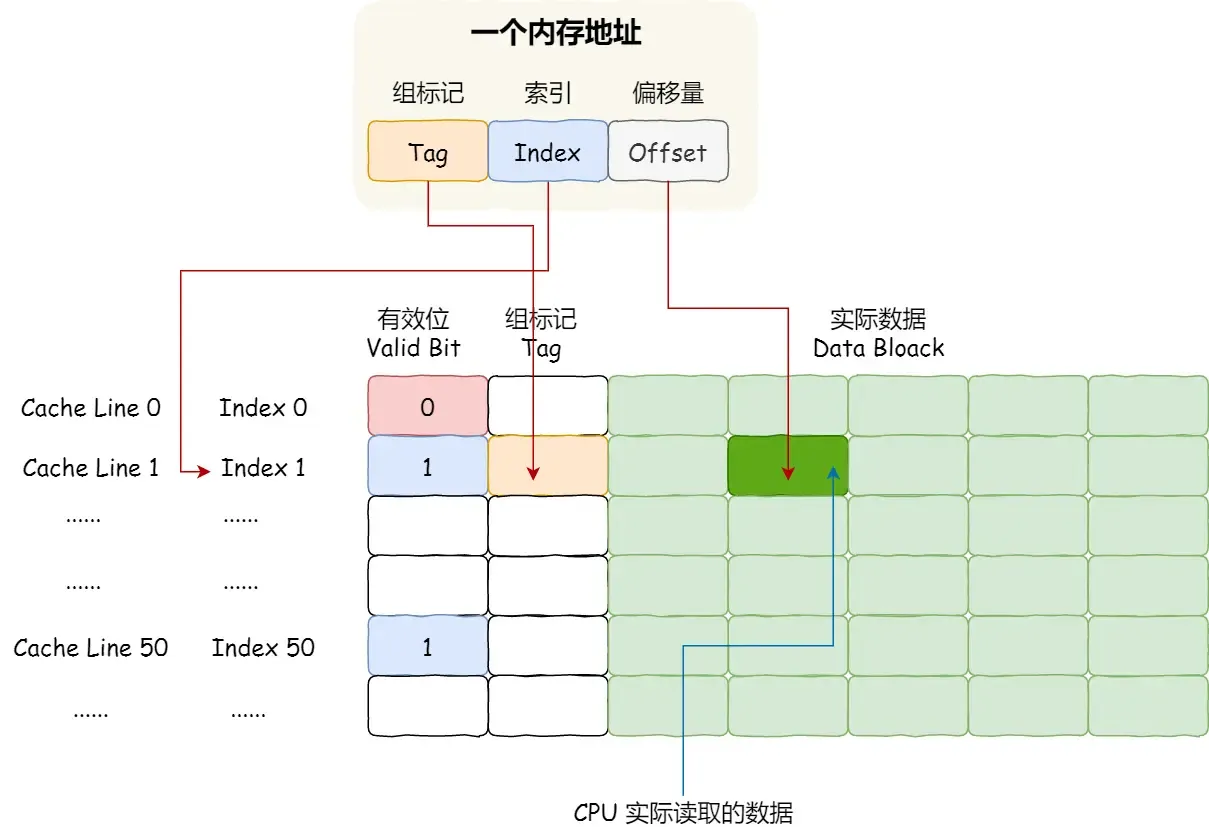 Cache Line 包含以下部分
Cache Line 包含以下部分
- 标记头(Tag)
- 有效位:表示该缓存行是否有效
- 组标记:用于与缓存行中的组标记对比,确认是否命中
- 其他标记(脏位等)
- 实际数据
内存地址包含三个部分
- 组标记:用于与缓存行中的组标记对比,确认是否命中
- 索引:用于选择缓存行
- 偏移量:用于在缓存行中定位具体的字节
当 CPU 需要根据内存地址读取一个内存块时,步骤如下:
- 根据索引定位缓存行
- 检查有效位,
- 对比缓存行的组标记和内存地址的组标记
- 缓存行有效,且组标记相等,说明缓存命中,根据偏移量,从缓存块读取对应的数据
缓存行-内存块的映射策略
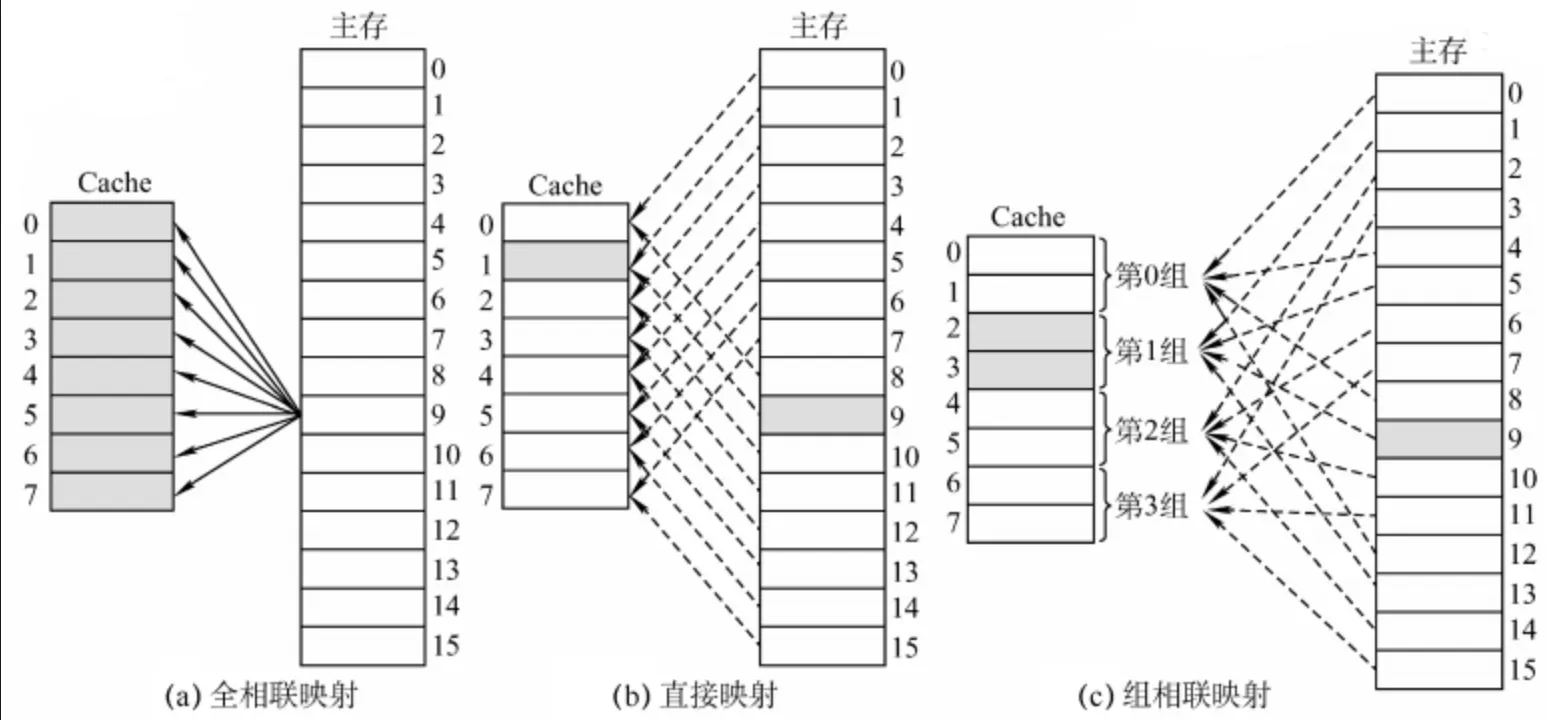
- 全相联:每一个内存块可以随意存放在任意缓存行
- 读取一个主存块时,找到第一个空的缓存行,如果没有则根据淘汰策略(LRU、FIFO 等)淘汰掉一行,存放时将缓存行的标记位改为主存块的标记位
- 后续读取时,并行地将所有缓存行的标记位和内存地址的标记位对比,找到目标缓存行,检查有效位
- 直接映射:每一个内存块存放在固定的缓存行
缓存行索引 = 内存块索引 % 缓存行数
- 组相联:每一个内存块可以存放在固定的缓存组中的任意一行
缓存组索引 = 内存块索引 % 缓存组数- 读取内存块时,根据索引找到目标组,找到组内的第一个空行,如果没有则根据淘汰策略淘汰,存放时将缓存行的标记位改为主存块的标记位
- 后续读取时,根据索引找到目标组,并行地将组内所有的缓存行的标记位和内存地址的标记位对比,找到目标缓存行,检查有效位
取模技巧
取模时可以利用公式 x % 2^n = x & (2^n - 1)
提高缓存命中率
- 数据缓存:按照内存顺序读写数据
- 指令缓存:将数据预处理为分支预测友好的(例如先排序,再比较大小),分支预测会预先将目标分支中的指令加载到缓存
- 多核的缓存命中率:对于数据强相关的「计算密集型」的任务,让多个线程在同一个核心上运行,利用核心的 L1 L2 缓存;对于两个数据无关的任务,应该跑在不同的核心上,避免无关数据互相将对方挤出缓存
缓存一致性
CPU 更新数据的策略
- 写直达
- 每次写数据,检查数据是否在 CPU Cache 中
- 如果缓存中有,则更新缓存然后更新主存
- 如果没有则直接更新主存
- 写回 - 每次写数据,判断缓存中是否有数据 - 如果有数据则只更新缓存 - 如果没有则从主存中读取并写入缓存,更新缓存 - 写入缓存时要检查缓存内是否有其他的旧数据,如果有检查是否为脏数据,如果为脏数据,将脏数据写回主存
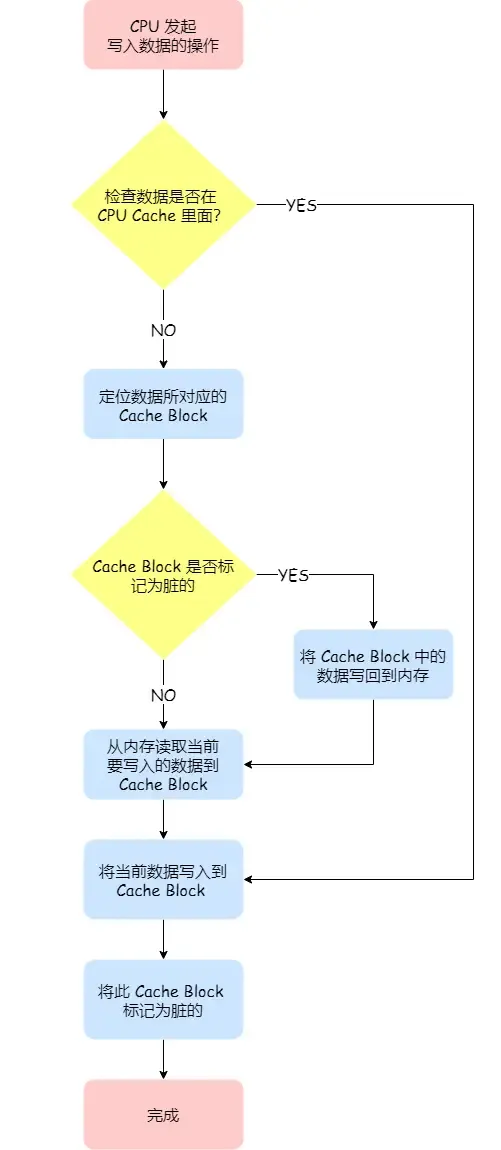
写回策略会导致不同核心的缓存不一致,各自对缓存修改并写回有不确定性 要解决缓存不一致问题要做到两点:
- 写传播:当一个核心修改 Cache 中的变量后,要传播到其他核心的 Cache
- 串行化:其他核心看到的数据变化顺序必须是一致的
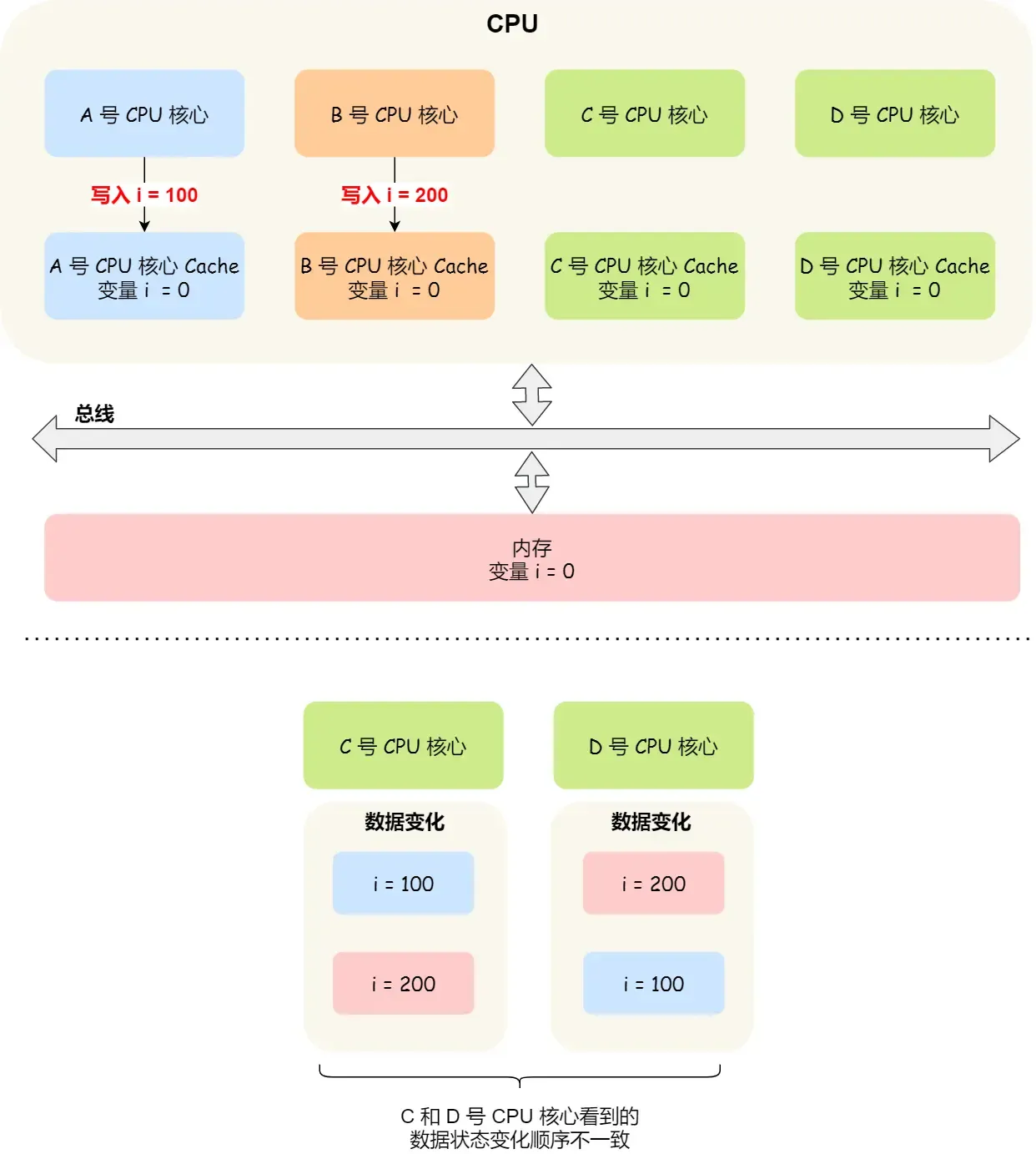
MESI 协议
MESI 协议通过以下两个技术实现缓存一致性
- 状态机机制:规定 CPU Cache 有以下
- 已修改:
M (Modified) - 独占:
E (Exclusive) - 共享:
S (Shared) - 已失效:
I (Invalidated)
- 已修改:
- 总线嗅探
- 所有核心会监听总线上的请求,读取和修改数据都会向总线发送请求
- 核心读取数据时
- 如果缓存命中则直接读缓存
- 如果缓存未命中或者缓存中的目标数据状态为
I: 先发送请求到总线,如果其他核心有目标数据,就从其他核心的缓存中拿最新数据,如果数据原来状态为M/E则改为S;如果其他核心没有目标数据,则从主存中加载数据到缓存,状态设置为E
- 核心修改数据时
- 如果缓存未命中,则先读取数据到缓存,同上
- 如果缓存命中,检查目标数据状态:
如果为
M/E则直接修改 如果为S则发送 RFO(Read For Ownership)请求到总线,将其他核心中该数据的状态改为I,再修改数据,状态改为M
- 核心接收到 Read 请求,会检查自己的 Cache 中是否有对应的数据,如果有就会返回,并将数据状态改为
S;如果接收到 RFO 请求,会将对应数据的状态改为I
CPU 任务执行机制
伪共享问题
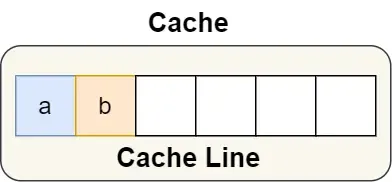
如果两个核心各有一个线程,两个线程分别需要对一个变量进行频繁修改,这两个变量如果在同一个缓存行中,会导致缓存中一个变量修改就会让另一个变量失效(见 MESI 协议),缓存命中率会大幅降低 避免伪共享的方法:
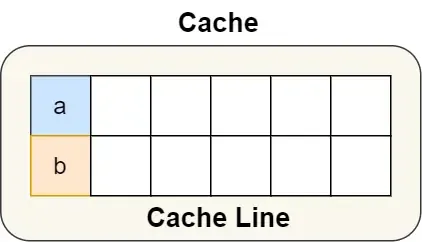
- linux 内核中有一个
__cacheline_aligned_in_smp宏定义,用于解决伪共享问题,这个宏定义会将变量的地址设置为缓存行对齐地址
struct {
int a;
int b;
}
struct {
int a;
int b __cacheline_aligned_in_smp;
}
- Java 并发框架 Disruptor 使用「字节填充 + 继承」的方式,来避免伪共享的问题
abstract class RingBufferPad {
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad {
// 其他字段...
private final long indexMask;
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
// 其他方法...
}
public final class RingBuffer<E> extends RingBufferFields<E>
implements Cursor, EventSequencer<E>, EventSink<E> {
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;
protected long p1, p2, p3, p4, p5, p6, p7;
// 其他字段和方法...
}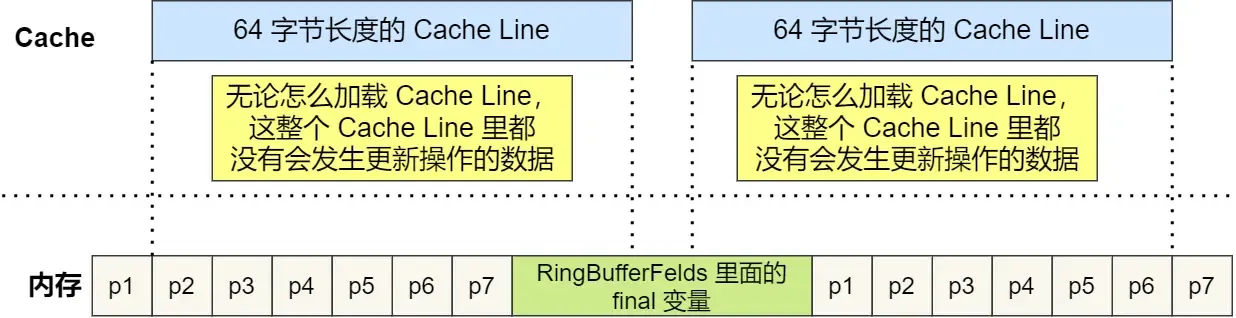 由于「前后」各填充了 7 个不会被读写的
由于「前后」各填充了 7 个不会被读写的 long 类型变量,所以无论怎么加载 Cache Line,这整个 Cache Line 里都没有会发生更新操作的数据,只要数据被频繁访问,就一直不会失效